The increasing availability and maturity of both scalable computing architectures and deep syntactic parsers is opening up new possibilities for Relation Extraction (RE) on ever-growing corpora of natural language text. Freepal is a resource designed to assist with the creation of relation extractors for more than 5,000 relations defined in the Freebase knowledge base. The resource consists of over 10 million distinct lexico-syntactic patterns defined over dependency trees, each of which is assigned to one or more Freebase relations with different confidence strengths.
The resource is generated by a large-scale distant supervision approach on the ClueWeb09 corpus to extract and parse over 260 million sentences labeled with Freebase entities and relations.
The dataset is released to the research community to evaluate our method further as well as use the findings as basis for building powerful relation extraction systems.
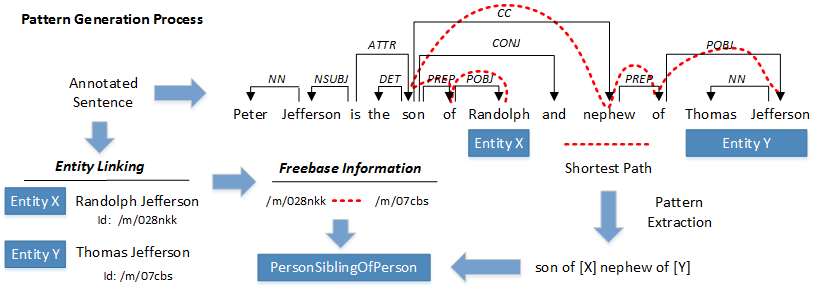
Patterns are extracted from the shortest undirected path between two annotated entities. The pattern is a candidate for all Freebase relations (in this case PersonSiblingOfPerson) that the two entities participate in.
This search interface allows you to browse and query the pattern database. In total there are 25427 patterns to explore. The pattern list is generated by selecting the 100 most common Freebase relations and for each up to 100 patterns respectively.
Search results are limited to return 1000 results at most. You can use boolean operators (AND, OR) to filter the results even further. The search is global across the pattern fields as well as the relationship name.
You can download the dataset in two different sizes.
If you need the dataset in a different format, please contact us.
{
"feature":"argue case [X] before [Y] [0-dobj-1,0-prep-3,1-appos-2,3-pobj-4]",
"relation":"ns:law.legal_case.court",
"entropy":0.6365141682948128,
"counts":6,
"relationcounts":4,
"sentence":"Justice Marshall successfully argued the 1954 landmark case Brown v. Board of Education before the U.S. Supreme Court.",
"freebaseId1":"/m/0hk56",
"freebaseId2":"/m/07sz1",
"uri":"http://www.csrwire.com/News/6640.html",
"entity1_offset_1":60,
"entity1_offset_2":87,
"entity2_offset_1":104,
"entity2_offset_2":117
}{
"feature":"argue case [X] before [Y] [0-dobj-1,0-prep-3,1-appos-2,3-pobj-4]",
"counts":12,
"entropy":1.3296613488547582,
"relationCount":[
{"relation":"ns:user.rca.default_domain.us_court_decision.court","count":2},
{"relation":"ns:law.court.legal_cases","count":4},
{"relation":"ns:law.legal_case.court","count":4},
{"relation":"ns:user.rca.default_domain.court.decision","count":2}
],
"toprelation":"ns:law.legal_case.court",
"toprelationcount":4
}If you use this data in a publication, please cite it using one of the following citations
Johannes Kirschnick, Alan Akbik, Holmer Hemsen, "Freepal: A Large Collection of Deep Lexico-Syntactic Patterns for Relation Extraction", in the 9th edition of the Language Resources and Evaluation Conference, LREC. 2014.
Johannes Kirschnick, Alan Akbik, Holmer Hemsen, "Freepal Dataset: A Large Collection of Deep Lexico-Syntactic Patterns for Relation Extraction", Version 1 (Release date 24.10.2013), October 2013
Last Updated July 2016
